|
Wanqi Xue (薛万祺)
I am a PhD student studying Computer Science at Nanyang Technological University. I am fortunate to be advised by Prof. Bo An and Prof. Chai Kiat Yeo.
My research focuses on reinforcement learning, multi-agent reinforcement learning, and their applications in security, recommendation and so on. Previously, I also worked on meta-learning and few-shot learning.
I have experience in large open-source projects. I am a main contributor and an ASF committer of Apache-SINGA, for which I developed the AutoGrad system.
Email /
CV /
GitHub /
Google Scholar /
LinkedIn
|

|
|
Selected Publications (Full list is in my CV)
|
|
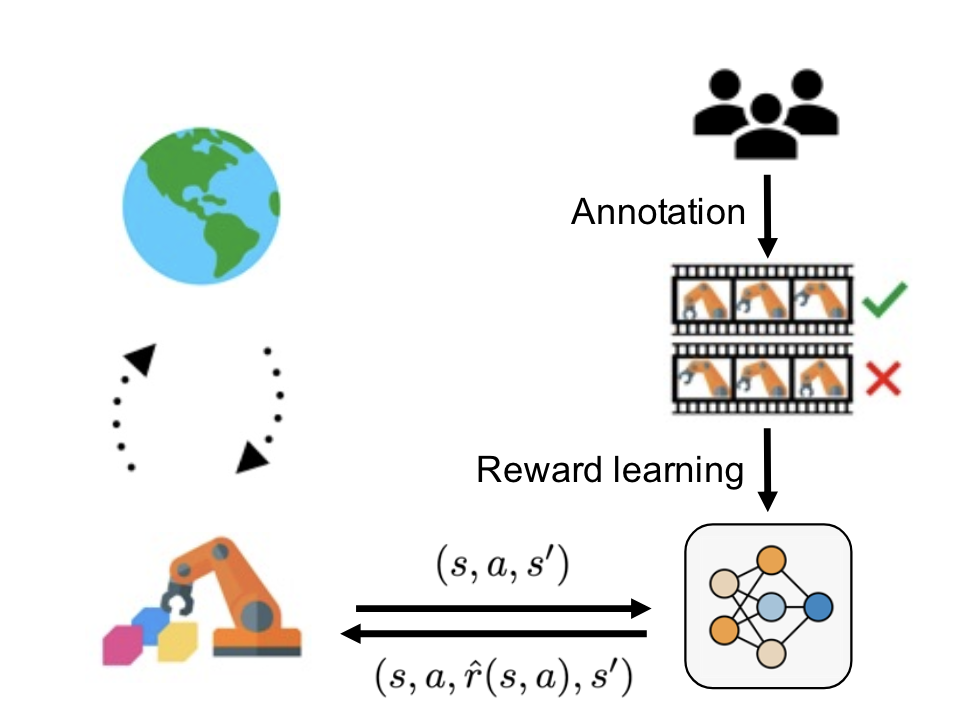
Reinforcement Learning from Diverse Human Preferences
Wanqi Xue,
Bo An, Shuicheng Yan, Zhongwen Xu
International Joint Conference on Artificial Intelligence
(IJCAI), 2024
Our focus is on addressing instability issues of RL policy learning caused by inconsistencies in human feedback. A simple yet effective method is proposed to stabilize the reward learning by constraining and correcting the predicted rewards within a latent space. Our method is able to effectively recover the performance of existing preference-based RL algorithms under diverse preferences in various tasks.
|

|
PrefRec: Recommender systems with human preferences for reinforcing long-term user engagement
Wanqi Xue,
Qingpeng Cai, Zhenghai Xue, Shuo Sun, Shuchang Liu, Dong Zheng, Peng Jiang, Kun Gai, Bo An
SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2023
We propose a new training paradigm, recommender systems with human preferences, which allows RL recommender systems to learn from human feedback/preferences on users’ historical behaviors rather than explicitly defined rewards. We demonstrate that RL from human preferences, a framework that has led to successful applications such as ChatGPT, is also applicable to recommender systems.
|
|
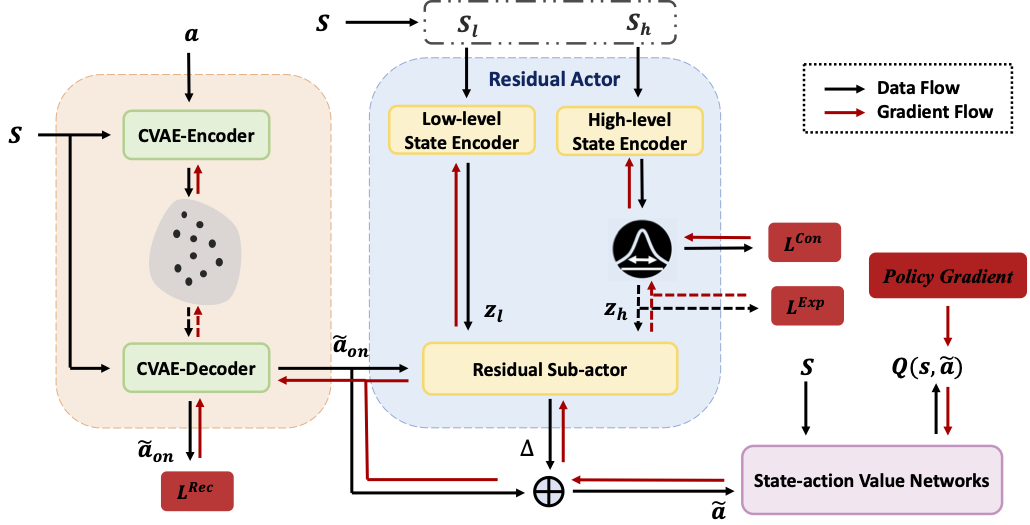
ResAct: Reinforcing
long-term engagement in sequential recommendation with residual actor
Wanqi Xue,
Qingpeng Cai, Ruohan Zhan, Dong Zheng, Peng Jiang, Kun Gai, Bo An
International Conference on Learning Representations (ICLR), 2023
To optimize long-term user engagement in sequential recommendation, we propose ResAct which seeks a policy that is close to, but better than, the online-serving policy. In this way, we can collect sufficient data near the learned policy so that state-action values can be properly estimated, and there is no need to perform online exploration.
|
|
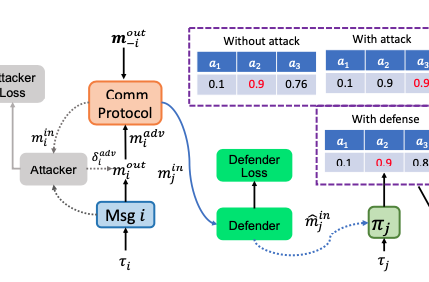
Mis-spoke or mis-lead: Achieving Robustness in Multi-Agent Communicative Reinforcement Learning
Wanqi Xue,
Wei Qiu, Bo An, Zinovi Rabinovich, Svetlana Obraztsova, Chai Kiat Yeo
International Conference on Autonomous Agents and Multiagent
Systems (AAMAS), 2022
(Oral presentation)
We systematically explore the problem of adversarial communication in multi-agent RL. The adversarial communication problem is formulated as a two-player zero-sum game and we propose a game-theoretical method R-MACRL to improve the worst-case performance.
|

|
NSGZero: Efficiently Learning Non-Exploitable Policy in Large-Scale Network Security Games with Neural Monte Carlo Tree Search
Wanqi Xue,
Bo An, Chai Kiat Yeo
AAAI Conference on Artificial Intelligence (AAAI), 2022 (Oral presentation)
We propose a model-based RL method, NSGZero, to learn a non-exploitable policy in NSGs. NSGZero improves data efficiency by performing planning with neural Monte Carlo Tree Search (MCTS). We enable neural MCTS with decentralized control, making NSGZero applicable to NSGs with many resources.
|

|
Solving Large-scale Extensive-form
Network Security Games via Neural Fictitious Self-play
Wanqi Xue,
Youzhi Zhang, Shuxin Li, Xinrun Wang, Bo An, Chai Kiat Yeo
International Joint Conference on Artificial Intelligence
(IJCAI), 2021
We propose a novel learning paradigm, NSG-NFSP, to solve large-scale extensive-form NSGs based on Neural Fictitious Self-Play (NFSP).
|
|
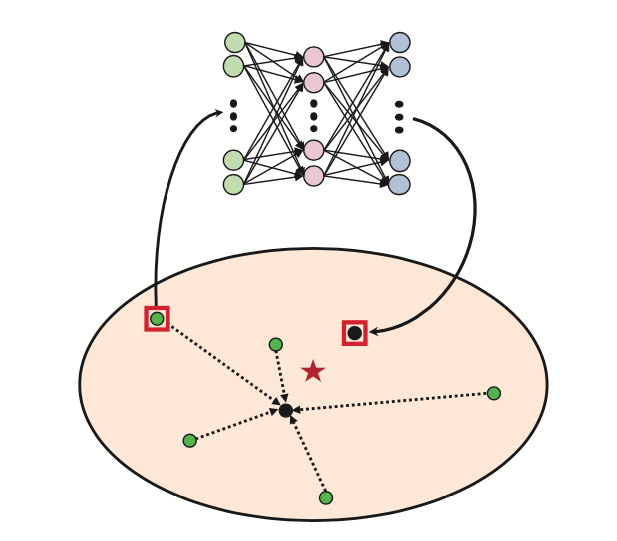
One-shot Image Classification by Learning to Restore Prototypes
Wanqi Xue,
Wei Wang
AAAI Conference on
Artificial Intelligence (AAAI), 2020
We propose a simple yet effective regression model, denoted by RestoreNet, which learns a class agnostic transformation on the image feature to move the image closer to the class center in the feature space.
|

|
Apache-SINGA is an Apache Top Level Project, focusing on distributed training of deep learning and machine
learning models.
I founded the Autograd system for Apache-SINGA, which is a key module for deep learning
frameworks. The AutoGrad system is able to perform automatic differentiation of a tensor.
Star
Fork
|
|